今年読んだ本
はじめに
この記事はサステナブルなぴょこりんクラスタ Advent Calendar 2023 - Adventarのために書いたものです。
やったこと
年末恒例ということで、amazonの履歴をみて、買った本を振り返ってみる。
一般書
心に余裕がなくてあまり読んでいないなあ…それでも一般書を上にすることで真面目な雰囲気のサムネをめざす。
- チームトポロジー

- GE帝国盛衰史

ライトノベル
今年は思ったより読んだ。個人的な好き属性にミートする作品をこぞって読んだ気がする。個人属性枠はガガガ文庫がなんか多い。
- ぼくたちのリメイク
")
往年の青春系美少女ゲームが好きな人ならはまりそうな気がする。
- 恋人以上のことを、彼女じゃない君と。
")
- 衛くんと愛が重たい少女たち
")
チューバのマウスピース選び
前提
今回記事は完全なる備忘録です。チューバ(E♭管)のマウスピースを買ったので、試したものを備忘録として残す。
経緯
もともとマウスピースにこだわりを持ったことがなく、高校2年くらいからずっとSchilke 69C4を使っていた。大学卒業までは吹奏楽だったのだが、いろいろあってブラスバンドでE♭ Bassを吹くことになった。しばらくはそのままSchilkeの69C4をE♭管でも使っていたが、どうやらE♭管とB管では違うマウスピースを使うのが一般的らしいと気づく()それで、私の好きなチューバ奏者のジョン・フレッチャーがBach 24AWを使っているらしいと聞き、試奏なしにぽちって使い始める()
数年間そのままBach 24AWを使っていたが、急に自分に合ったマウスピースを探すのがよいのではないかと思い立ち、翌日くらいにお世話になっている楽器屋さんに試奏のお願いをした。
来店後「どんな感じのマウスピースがいいですかね?」と聴かれて、いきなり困るが、「漠然と低音域を強化したい」という感じのことを伝える。そんな適当な状況でしたが、いろいろとピックアップしてもらった(ありがとうございます)。改めてみると店頭にあったベーシックなモデルを一通り並べて頂いた印象です。
試した銘柄
- Bach 24AW→リム内径:31.25mm、スロート径:8.33mm(*比較元)
- Conn Helleberg 7B→リム内径:32.00mm、スロート径:8.5mm
- Perantucci PT-65→リム内径:32.0mm、スロート径 7.8mm
- DenisWick Heritage 2L(GP,シルバー)→リム内径:32.50mm、スロート径 8.45mm
- DenisWick Heritage 3XL→リム内径:31.25mm、スロート径 8.78mm
- Willie's MK-E♭→リム内径:31.75mm スロート径:8.41mm
(データは、楽器屋さんのサイト調査による)
DenisWick Heritage 2L(GP)とWillie's MK-E♭の2択で悩む。
DenisWick Heritage 2L(GP)は全音域すごく鳴らしやすくてレスポンスがとてもいいのがよかった。
Willie's MK-E♭はDenisWickに比べて鳴らす難しさはあるものの、E♭管でもパワフルな響きがあるのがよかった。
で、うーんとなったけど、チューバらしい響きが出せるといいなという思いから、Willie's MK-E♭を買った。
その他
リム内径がちょっと小さすぎるものを使っていたかもと、今更ながら思った。マウスピースでどれだけ変わるんだろう~と思っていたけど、目から鱗でした。頑張って練習するぞ~!
フロントエンド頑張る編(React)
前置き
この記事は平穏な生活を送りたいぴょこりんクラスタ Advent Calendar 2022 - Adventarのために書かれたものです。
本題
やったこと
darumap.hatenablog.com
去年やっていた続きをやりました。
去年はMySQLで作ったデータベースから、データを引っこ抜いて返すバックエンド(express)を作りました。ということで、今年はようやくフロントエンド側に着手します。一応Reactで頑張る方向で。
+--------+--------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +--------+--------------+------+-----+---------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | food | varchar(255) | YES | | NULL | | | kind | varchar(255) | YES | | NULL | | | amount | int(11) | YES | | NULL | | +--------+--------------+------+-----+---------+----------------+ +----+-------+------+--------+ | id | food | kind | amount | +----+-------+------+--------+ | 1 | beef | meat | 2 | | 2 | pork | meat | 3 | | 3 | sushi | fish | 3 | +----+-------+------+--------+
バックエンド側でAPI叩くと上記のデータがMySQLからかえってくるようにして、kindに応じてそれぞれリストを表示するようにします。
http://localhost:3001/api/foodsを叩くと、返ってくるようにしています。
こんな感じに表示されるものを作りました。

ソースコードはこちら。
App.js
import './App.css'; import FoodList from './components/FoodList'; import React from "react"; import {useState, useEffect} from 'react'; import axios from 'axios'; const db_url = "http://localhost:3001/api/foods"; function App() { const [data, setData] = useState(0); useEffect(() =>{ axios.get(db_url).then((response) => { setData(response.data); }) },[]); console.log(data); if(!data) return null; const data_m = data.filter( (datum) => { return datum.kind === 'meat'; }); const data_f = data.filter( (datum) => { return datum.kind === 'fish'; }); return ( <div className="App"> <FoodList title='meat' data={data_m}/> <FoodList title='fish' data={data_f}/> </div> ); } export default App;
component/FoodList.jsx
import * as React from 'react'; import Table from '@mui/material/Table'; import TableBody from '@mui/material/TableBody'; import TableCell from '@mui/material/TableCell'; import TableContainer from '@mui/material/TableContainer'; import TableHead from '@mui/material/TableHead'; import TableRow from '@mui/material/TableRow'; import Paper from '@mui/material/Paper'; export default function FoodList(props) { return ( <div> <h1>{props.title}</h1> <TableContainer component={Paper} sx={{ display: 'flex', maxWidth: 800, m: 'auto' }} > <Table aria-label="simple table"> <TableHead> <TableRow> <TableCell>Food</TableCell> <TableCell align="right">amount</TableCell> </TableRow> </TableHead> <TableBody> {props.data.map((row) => ( <TableRow key={row.food} sx={{ '&:last-child td, &:last-child th': { border: 0 }}} > <TableCell component="th" scope="row"> {row.food} </TableCell> <TableCell align="right">{row.amount}</TableCell> </TableRow> ))} </TableBody> </Table> </TableContainer> </div> ); }
感想
何かをやろうとするとcss, js, Reactの各レイヤの知識が混然と求められるので正直大変な印象。それぞれ頑張らんと…。
フロントエンドに強くなりたい(初歩)
前置き
この記事は異世界行ったら本気だすぴょこりんクラスタ Advent Calendar 2021 - Adventarのために書かれたものです。
前提
もうちょっとパパっとwebアプリケーションを作れるようになりたいので、こういう機会をチャンスとして仕込んでおく。なお私のこの辺の知識はほぼゼロであるので、多分読んでも学びはない気がします...。初歩的な目標として、データベースに入っているデータをバックエンド側で読み込んでフロントエンド側で可視化する、というところをめざす。
とりあえず、なんかそれっぽい感じで
- フロントエンド:vue.js(ただし今回ここまでたどりつかなかった・・・)
- バックエンド:node.js
- データベース:MySQL
でやる。
やったこと
フロントエンド側でリクエスト飛ばしてレスポンスを表示するところが時間切れだった。。とりあえずWSLのubuntu18.04上で動かす。
MySQLでデータベースを作る
MySQLをインストールする。この辺の初期設定はあやしい・・・
sudo apt install mysql-server sudo mysql_secure_installation sudo mysql
ユーザを作り、テスト用のテーブルを作る。
CREATE USER 'hayap'@'localhost' IDENTIFIED BY '(PASSWORD)'; #パスワードポリシーがMID以上だと特殊文字を入れてないとはじかれる、厳しい CREATE DATABASE FOOD; CREATE TABLE foods (id INT AUTO_INCREMENT, name TEXT, num INT, PRIMARY KEY (id)) DEFAULT CHARSET=utf8; (データ挿入は略) mysql> SELECT * FROM foods; +----+-------+------+ | id | name | num | +----+-------+------+ | 1 | SUSHI | 2 | | 2 | STEAK | 5 | +----+-------+------+ 2 rows in set (0.00 sec)
node.jsからMySQLにつなぐ
下記のmysqlモジュールをつっこめばつながりそう。
www.npmjs.com
npmでインストール
npm install mysql
test.jsとして作成
const mysql = require('mysql');
const connection = mysql.createConnection({
host: 'localhost',
user: 'hayap',
password: '(PASSWORD)',
database: 'FOOD'
});
connection.connect();
connection.query('SELECT * FROM foods', (error, results) => {
console.log(results[0]);
});
connection.end(); 実行
node test.js
RowDataPacket { id: 1, name: 'SUSHI', num: 2 }でOK.
データベースの中身をレスポンスとして返す
バックエンド側でリクエストを受けて、データベースの中身を返すようにする。
expressモジュールでルーティング処理を書いてやる。server.jsとして作成。
const express = require('express');
const app = express();
const mysql = require('mysql');
const connection = mysql.createConnection({
host: 'localhost',
user: 'hayap',
password: '(PASSWORD)',
database: 'FOOD'
});
app.get('/test', (req,res) =>
res.send({message: 'Hello World!'
})
);
app.get('/api/foods', (req,res) => {
connection.connect();
connection.query('SELECT * FROM foods', (error, results) => {
res.send(results);
});
connection.end();
});
app.listen(process.env.PORT || 3000);これで、node server.jsして、http://localhost:3000/api/foodsにアクセスするとデータベースの中身がかえってくる。
最後に
引き続き頑張ってYATTEIKI。
今年読んだ本について
前置き
この記事はニューノーマル ぴょこりんクラスタ Advent Calendar 2020 - Adventarのために書かれたものです。
前提
今年読んだ本について振り返る。
本文
漫画
すべての人類を破壊する。それらは再生できない。
web-ace.jp
「マジック:ザ・ギャザリング(MtG)」×90年代ノスタルジーな感じな漫画。ぶっささる世代は私よりもうちょっと上かな?1999年とかなので。でも要所のエモみがある。私はMtGは未経験なのですが(コロコロコミックとか流行っていた記憶)、雰囲気が好きで読んでいるシリーズ。
BLUE GIANT
www.shogakukan.co.jp
ジャズ漫画で、主人公がジャズプレーヤーとして活躍していく道筋を描くもの。無印(日本編)→SUPREME(ヨーロッパ編)→EXPLORER(アメリカ編)で、先日SUPREMEが完結したところ。月並みですが、ライブの熱量がすごい。
一般書籍(?)
バブル―日本迷走の原点―
www.shinchosha.co.jp
バブルの歴史をマクロな流れを俯瞰しつついくつかの事件を紹介しながら描いたもの。崩壊後の混乱みたいなものを想定していたが、そうではなくバブルの最中に何が起きていたのか、を中心に記載したもの。金融情勢の記載が中心なので(無学なこともあり)ちょっと目が滑ったが、面白かった。
ブリッツスケーリング
www.nikkeibp.co.jp
新事業立ち上げにおいて、猛烈なスピードで事業成功をおさめたケースに着目し、これを実現するメカニズムに迫った本。直近のビジネスにおいては、利用者数の増大が価値をもつタイプのものが多く、これらは類似サービスの中でトップシェアを確保できないと死んでしまう。なので、あるフェーズまではとにかく利用者数を稼ぐことに全力を注ぐべし。なので拡大の仕組みが肝になる。という趣旨。
まとめ
今年はライトノベルを全く読まなかったなと。。。
データドリブンお酒探しに向けて
前置き
この記事はニューノーマル ぴょこりんクラスタ Advent Calendar 2020 - Adventarのために書かれたものです。
前提
年末にふるさと納税を使って日本酒を飲むことをしているが、データでイケてる日本酒を探したいと思っていた。そんなところで、日本酒にまつわるデータを見つけたので、これを使って何かできないかを探ってみている。
使ったデータ
日本酒アプリ さけのわhttps://sakenowa.comのデータセットが公開されており、これを使ってみることとする。さけのわデータプロジェクト | さけのわに、API、データ仕様の記載がある。
アプリ内でのレビューをもとに、日本酒のフレーバーを数値化したデータやフレーバーにかかわるタグテキスト等、を公開している。
今回は、フレーバー情報に基づいてお酒を俯瞰してみることとする。フレーバーチャート情報を使う。
{
"flavorChart": [
{
"brandId": 2,
"f1": 0.257238459795324,
"f2": 0.424835098066976,
"f3": 0.353698484182939,
"f4": 0.480473334729331,
"f5": 0.47061712325654,
"f6": 0.419411247406479
},
{
"brandId": 7,
"f1": 0.267467145120062,
"f2": 0.377822546680296,
"f3": 0.289076396929994,
"f4": 0.747658835061302,
"f5": 0.239046174961479,
"f6": 0.293273726798657
}
]
}
brandId:銘柄ID(別データとして取得)
f1:華やか
f2:芳醇
f3:重厚
f4:穏やか
f5:ドライ
f6:軽快
といったように、フレーバーの傾向を6分類し、その大きさを数値化したデータである。(数値化については、レビューの単語の出現頻度等を活用している模様)
やったこと
主成分分析を行い、2次元にデータを圧縮し、可視化を行う。
データの読み込み
取得したデータはローカルに保存し、これを読み込む。
import pandas as pd import json f = open('./data/flavor-charts.json','r') data_dict = json.load(f) df = pd.DataFrame(data_dict['flavorCharts']) df = df.set_index('brandId') print(df.head())
f1 f2 f3 f4 f5 f6 brandId 2 0.267943 0.426314 0.345169 0.498422 0.458045 0.411208 7 0.268666 0.367453 0.269238 0.724820 0.322863 0.301171 9 0.526624 0.427194 0.178750 0.474636 0.279828 0.452369 10 0.377608 0.324050 0.230461 0.370407 0.567223 0.490254 11 0.297464 0.414633 0.547268 0.563140 0.211284 0.279867
でOKそう。
データの可視化
データを散布図に可視化してみる。
from pandas import plotting import matplotlib.pyplot as plt plotting.scatter_matrix(df) plt.show()
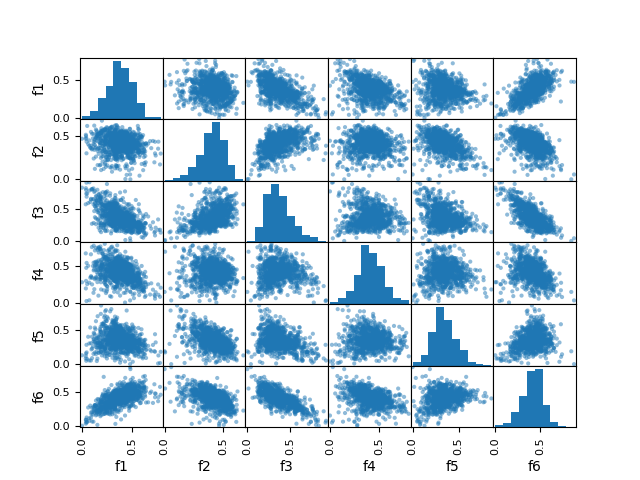
いくつかの要素は相関がありそう。
データの標準化
主成分分析をするので、平均0,分散1に各データを標準化しておく。
dfs = df.apply(lambda x: (x - x.mean())/x.std(), axis=0) print(dfs.head())
f1 f2 f3 f4 f5 f6 brandId 2 -0.858334 0.172921 -0.163503 0.678053 0.863875 -0.016120 7 -0.852646 -0.383120 -0.673862 2.380670 -0.176327 -0.945029 9 1.177873 0.181233 -1.282064 0.499175 -0.507468 0.331358 10 0.004893 -0.793129 -0.934495 -0.284677 1.703972 0.651175 11 -0.625960 0.062572 1.194878 1.164762 -1.034905 -1.124872
主成分分析
主成分分析をして、データの次元削減をする。寄与率と主成分ベクトルを確認する。
import sklearn from sklearn.decomposition import PCA pca = PCA() pca.fit(dfs) print(pca.explained_variance_ratio_) print(pca.components_)
[0.45513933 0.24587843 0.15350358 0.08774033 0.03962648 0.01811186] [[-0.43195544 0.37624031 0.51930317 0.18089127 -0.25005763 -0.55401397] [-0.47696351 -0.41993863 -0.10348769 0.49205099 0.57563075 -0.10946561] [-0.23236591 -0.10872116 0.3814615 -0.76426028 0.45216375 0.01127334] [ 0.03878308 -0.79990729 0.3498008 -0.01081215 -0.485031 -0.03019307] [-0.60138986 0.13150583 0.04243996 0.0300543 -0.28075088 0.73451412] [-0.41079497 -0.11458196 -0.67077559 -0.37423286 -0.29595985 -0.37488145]]
第1、第2主成分までで7割程度の寄与率、第4主成分までで9割超の寄与率となっている。第1主成分ベクトルはf2,f3が正、f1,f6が負となる方向(重厚・芳醇であり、華やか・軽快でない方向、とみなせる)で、第2主成分ベクトルはf4,f5が正、f1,f2が負となる方向(穏やか・ドライであり、華やか・芳醇でない方向、とみなせる)。
2次元上での可視化
第1主成分、第2主成分までで、データをプロットしてみる。
data_trans = pca.transform(dfs) plt.scatter(data_trans[:,0],data_trans[:,1]) plt.xlabel('PC1') plt.ylabel('PC2') plt.show()
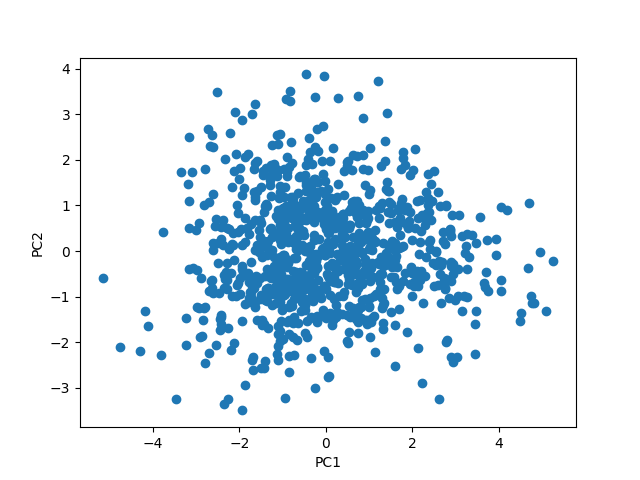
もう少しクラスタっぽくなるかも思ったが、全体的にもちゃっとしている・・・
第1、第2主成分が最大、最小となる酒をみてみる。
f = open('./data/brands.json','r') brands = json.load(f)['brands'] brands_dict = {} for i in brands: brands_dict[i['id']] = i['name'] dfss = pd.DataFrame(data_trans,index=df.index) print(brands_dict[dfss.loc[:,0].idxmax()]) print(brands_dict[dfss.loc[:,0].idxmin()]) print(brands_dict[dfss.loc[:,1].idxmax()]) print(brands_dict[dfss.loc[:,1].idxmin()])
ダルマ正宗:第1主成分最大 夏どぶろっく:第1主成分最小 越生梅林:第2主成分最大 花陽浴:第2主成分最小
ぐぐった感じだと傾向はあっていそう。
まとめ
日本酒のフレーバーデータに対して、主成分分析を適用し、酒の傾向を分析しました。自分の飲酒履歴からの照らし合わせ等もやっていきたいです。
今年読んだ本について
前置き
この記事は圧倒的令和ッ!!ぴょこりんクラスタ Advent Calendar 2019 - Adventarのために書かれたものです。ちなみにこのACが何なのかについては、ぴょこりんクラスタ Advent Calendar is 何? - ぴょこりんブログが詳しいです。
前提
ネタがありません。あるお方からのアドバイスに準じ、今年読んだ本について書きます。あくまで私が今年読んだ本であり、今年発売になった本ではないです。
漫画・ライトノベルの部
- ブルーピリオド(山口つばさ)
 (アフタヌーンコミックス)")
ちなみに先日発売された6巻までで一区切りという所(続くけど)なので、まとめ買いするにもちょうどよいかも。

ちなみに読み始めたのは
https://honto.jp/booktree/detail_00010097.html
のせいです。よくみたらこれは漫画版の方だったけど。
 (イブニングコミックス)")
一般書籍(?)の部
- アヘン王国潜入記(高野秀行)
")
- 申し訳ない、御社をつぶしたのは私です。(著:カレン・フェラン 訳:神崎朗子)

- 作者:カレン・フェラン
- 出版社/メーカー: 大和書房
- 発売日: 2014/03/26
- メディア: 単行本
やや失敗事例・原因分析が単純すぎでは?と思うシーンもあったが、下記などを述べている。
- 方法論・ツールには前提があり、万事に使えるものではない。まずは組織の課題を見定めるべき。
- 方法論・ツールを導入することで、業務プロセスと人間を切り離して考え、本質的な課題から目を背けることになりがち。
- 安易にある部署で新しい仕組みを増やすことが局所最適化につながり、組織としての最適化がなされなくなることがある。
耳が痛いですね。
- 沖縄現代史(桜澤誠)
")
昨年沖縄に行って、沖縄のことを知らなすぎると思い、買った本。立場によって見え方が異なると思うので、この一冊がどういう立ち位置にあるのか判断ができないが、勉強になった。
おわりに
kindleの中が漫画だらけでワロタ。