データドリブンお酒探しに向けて
前置き
この記事はニューノーマル ぴょこりんクラスタ Advent Calendar 2020 - Adventarのために書かれたものです。
前提
年末にふるさと納税を使って日本酒を飲むことをしているが、データでイケてる日本酒を探したいと思っていた。そんなところで、日本酒にまつわるデータを見つけたので、これを使って何かできないかを探ってみている。
使ったデータ
日本酒アプリ さけのわhttps://sakenowa.comのデータセットが公開されており、これを使ってみることとする。さけのわデータプロジェクト | さけのわに、API、データ仕様の記載がある。
アプリ内でのレビューをもとに、日本酒のフレーバーを数値化したデータやフレーバーにかかわるタグテキスト等、を公開している。
今回は、フレーバー情報に基づいてお酒を俯瞰してみることとする。フレーバーチャート情報を使う。
{
"flavorChart": [
{
"brandId": 2,
"f1": 0.257238459795324,
"f2": 0.424835098066976,
"f3": 0.353698484182939,
"f4": 0.480473334729331,
"f5": 0.47061712325654,
"f6": 0.419411247406479
},
{
"brandId": 7,
"f1": 0.267467145120062,
"f2": 0.377822546680296,
"f3": 0.289076396929994,
"f4": 0.747658835061302,
"f5": 0.239046174961479,
"f6": 0.293273726798657
}
]
}
brandId:銘柄ID(別データとして取得)
f1:華やか
f2:芳醇
f3:重厚
f4:穏やか
f5:ドライ
f6:軽快
といったように、フレーバーの傾向を6分類し、その大きさを数値化したデータである。(数値化については、レビューの単語の出現頻度等を活用している模様)
やったこと
主成分分析を行い、2次元にデータを圧縮し、可視化を行う。
データの読み込み
取得したデータはローカルに保存し、これを読み込む。
import pandas as pd import json f = open('./data/flavor-charts.json','r') data_dict = json.load(f) df = pd.DataFrame(data_dict['flavorCharts']) df = df.set_index('brandId') print(df.head())
f1 f2 f3 f4 f5 f6 brandId 2 0.267943 0.426314 0.345169 0.498422 0.458045 0.411208 7 0.268666 0.367453 0.269238 0.724820 0.322863 0.301171 9 0.526624 0.427194 0.178750 0.474636 0.279828 0.452369 10 0.377608 0.324050 0.230461 0.370407 0.567223 0.490254 11 0.297464 0.414633 0.547268 0.563140 0.211284 0.279867
でOKそう。
データの可視化
データを散布図に可視化してみる。
from pandas import plotting import matplotlib.pyplot as plt plotting.scatter_matrix(df) plt.show()
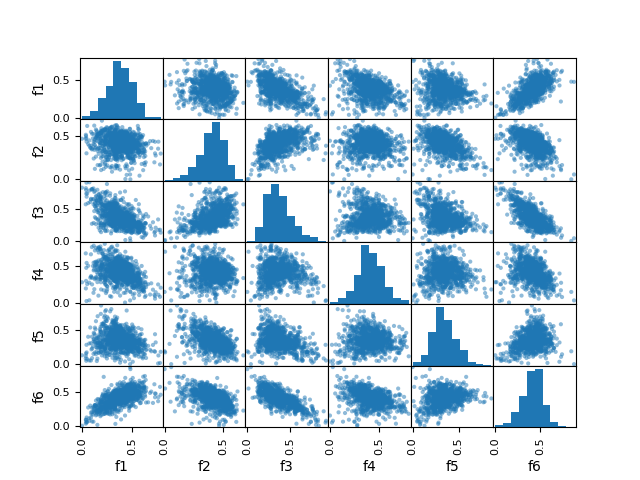
いくつかの要素は相関がありそう。
データの標準化
主成分分析をするので、平均0,分散1に各データを標準化しておく。
dfs = df.apply(lambda x: (x - x.mean())/x.std(), axis=0) print(dfs.head())
f1 f2 f3 f4 f5 f6 brandId 2 -0.858334 0.172921 -0.163503 0.678053 0.863875 -0.016120 7 -0.852646 -0.383120 -0.673862 2.380670 -0.176327 -0.945029 9 1.177873 0.181233 -1.282064 0.499175 -0.507468 0.331358 10 0.004893 -0.793129 -0.934495 -0.284677 1.703972 0.651175 11 -0.625960 0.062572 1.194878 1.164762 -1.034905 -1.124872
主成分分析
主成分分析をして、データの次元削減をする。寄与率と主成分ベクトルを確認する。
import sklearn from sklearn.decomposition import PCA pca = PCA() pca.fit(dfs) print(pca.explained_variance_ratio_) print(pca.components_)
[0.45513933 0.24587843 0.15350358 0.08774033 0.03962648 0.01811186] [[-0.43195544 0.37624031 0.51930317 0.18089127 -0.25005763 -0.55401397] [-0.47696351 -0.41993863 -0.10348769 0.49205099 0.57563075 -0.10946561] [-0.23236591 -0.10872116 0.3814615 -0.76426028 0.45216375 0.01127334] [ 0.03878308 -0.79990729 0.3498008 -0.01081215 -0.485031 -0.03019307] [-0.60138986 0.13150583 0.04243996 0.0300543 -0.28075088 0.73451412] [-0.41079497 -0.11458196 -0.67077559 -0.37423286 -0.29595985 -0.37488145]]
第1、第2主成分までで7割程度の寄与率、第4主成分までで9割超の寄与率となっている。第1主成分ベクトルはf2,f3が正、f1,f6が負となる方向(重厚・芳醇であり、華やか・軽快でない方向、とみなせる)で、第2主成分ベクトルはf4,f5が正、f1,f2が負となる方向(穏やか・ドライであり、華やか・芳醇でない方向、とみなせる)。
2次元上での可視化
第1主成分、第2主成分までで、データをプロットしてみる。
data_trans = pca.transform(dfs) plt.scatter(data_trans[:,0],data_trans[:,1]) plt.xlabel('PC1') plt.ylabel('PC2') plt.show()
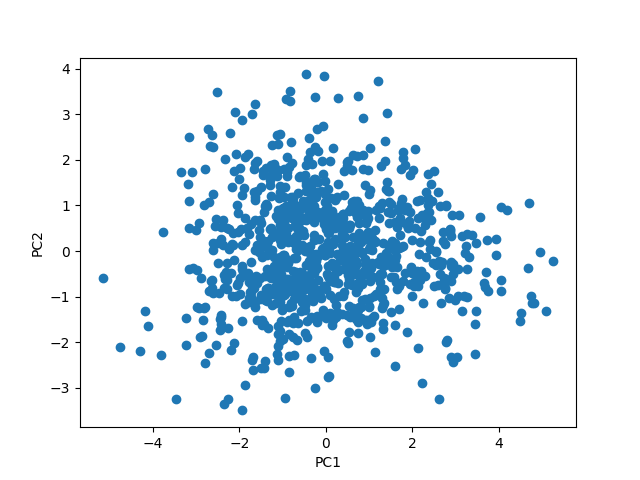
もう少しクラスタっぽくなるかも思ったが、全体的にもちゃっとしている・・・
第1、第2主成分が最大、最小となる酒をみてみる。
f = open('./data/brands.json','r') brands = json.load(f)['brands'] brands_dict = {} for i in brands: brands_dict[i['id']] = i['name'] dfss = pd.DataFrame(data_trans,index=df.index) print(brands_dict[dfss.loc[:,0].idxmax()]) print(brands_dict[dfss.loc[:,0].idxmin()]) print(brands_dict[dfss.loc[:,1].idxmax()]) print(brands_dict[dfss.loc[:,1].idxmin()])
ダルマ正宗:第1主成分最大 夏どぶろっく:第1主成分最小 越生梅林:第2主成分最大 花陽浴:第2主成分最小
ぐぐった感じだと傾向はあっていそう。
まとめ
日本酒のフレーバーデータに対して、主成分分析を適用し、酒の傾向を分析しました。自分の飲酒履歴からの照らし合わせ等もやっていきたいです。